6. ROC 曲线和 AUC
ROC :Receiver Operating Characteristic Curve,接收者操作特征曲线。
横坐标:False Positive Rate(FPR),即负例样本的预测错误率(越小越好)
\[FPR = \frac{FP}{N} = \frac{FP}{TN + FP}\]
纵坐标:True Positive Rate(TPR)/Recall/Hit Rate/Sensitivity,即正例样本的预测正确率(越大越好)
\[TPR = \frac{TP}{P} = \frac{TP}{TP + FN}\]
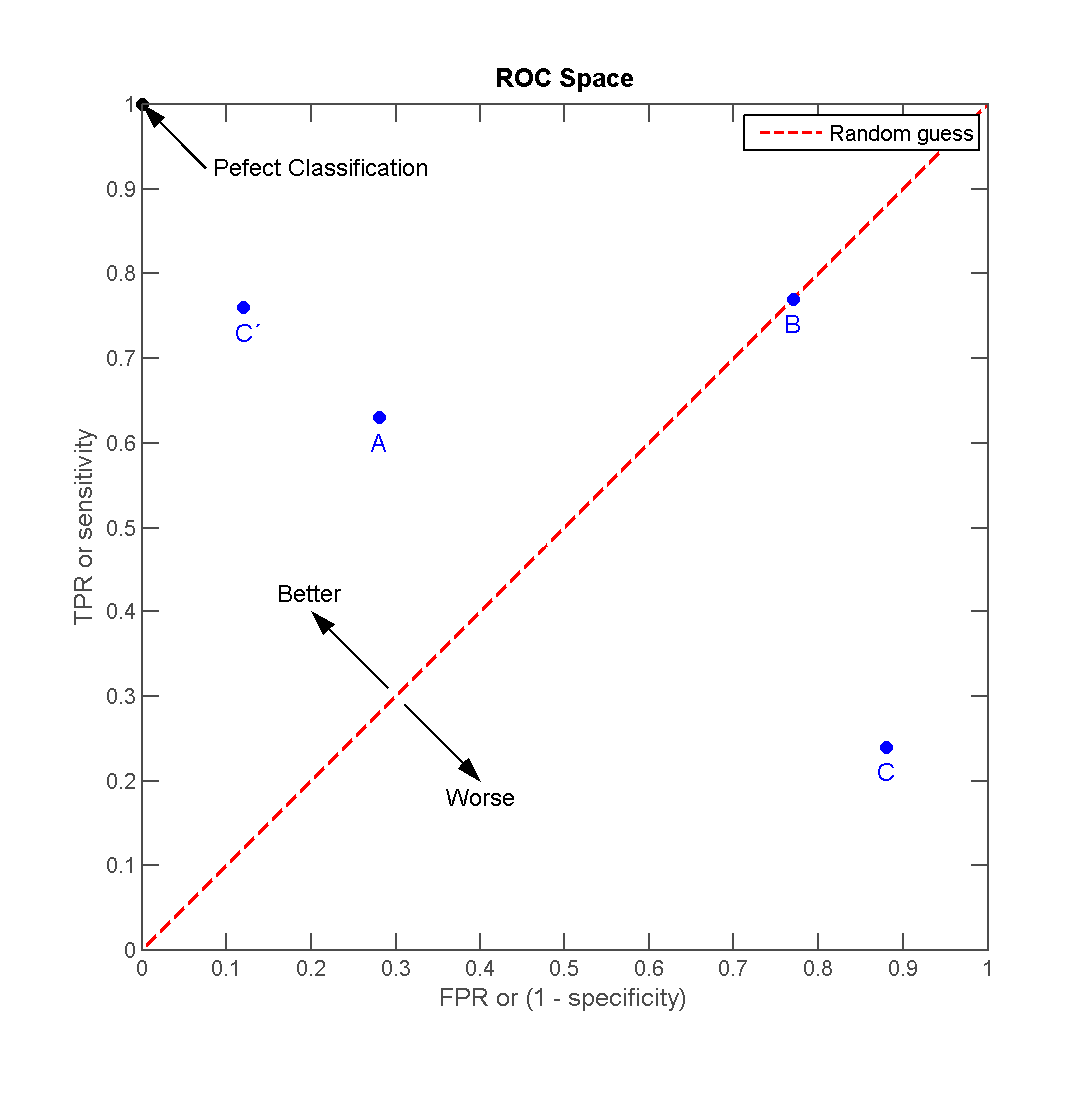
离左上角越近的点预测 Accuracy 越高。
在 A、B、C 三者当中,最好的是 A 方法。
B 的 Accuracy 是 50%。
C’ 与 C 互为镜像点,不管 C 预测了什么,C’ 就做相反的预测。
6.1. 基本概念
ROC 分析的是二元分类模型。
2 类标签:
Positive(P):正例
Negative(N):负例
4 种预测结果:
True Positive(TP):预测为正例,且预测正确。
False Positive(FP):预测为正例,但预测错误。
True Negative(TN):预测为负例,且预测正确。
False Negative(FN):预测为负例,但预测错误。
常用评价指标:
正确率(Accuracy)
准确率(Precision,Positive Predictive Palue - PPV)
召回率(Recall,Hit rate,Sensitivity,True Positive Rate - TPR)
F1 Score(准确率和召回率的调和平均)
\(2 \times 2\) 混淆矩阵(Confusion Matrix):

6.2. AUC
ROC 空间里的单点是给定分类模型且给定得分阈值后得出的,但同一个二元分类模型的阈值可能设定为高或低,每种阈值的设定会得出不同的 FPR 和 TPR。 一般地,减小阈值,FPR 和 TPR 都会增大。 将同一模型每个阈值的 (FPR, TPR) 坐标都画在 ROC 空间里,就成为特定模型的 ROC 曲线。
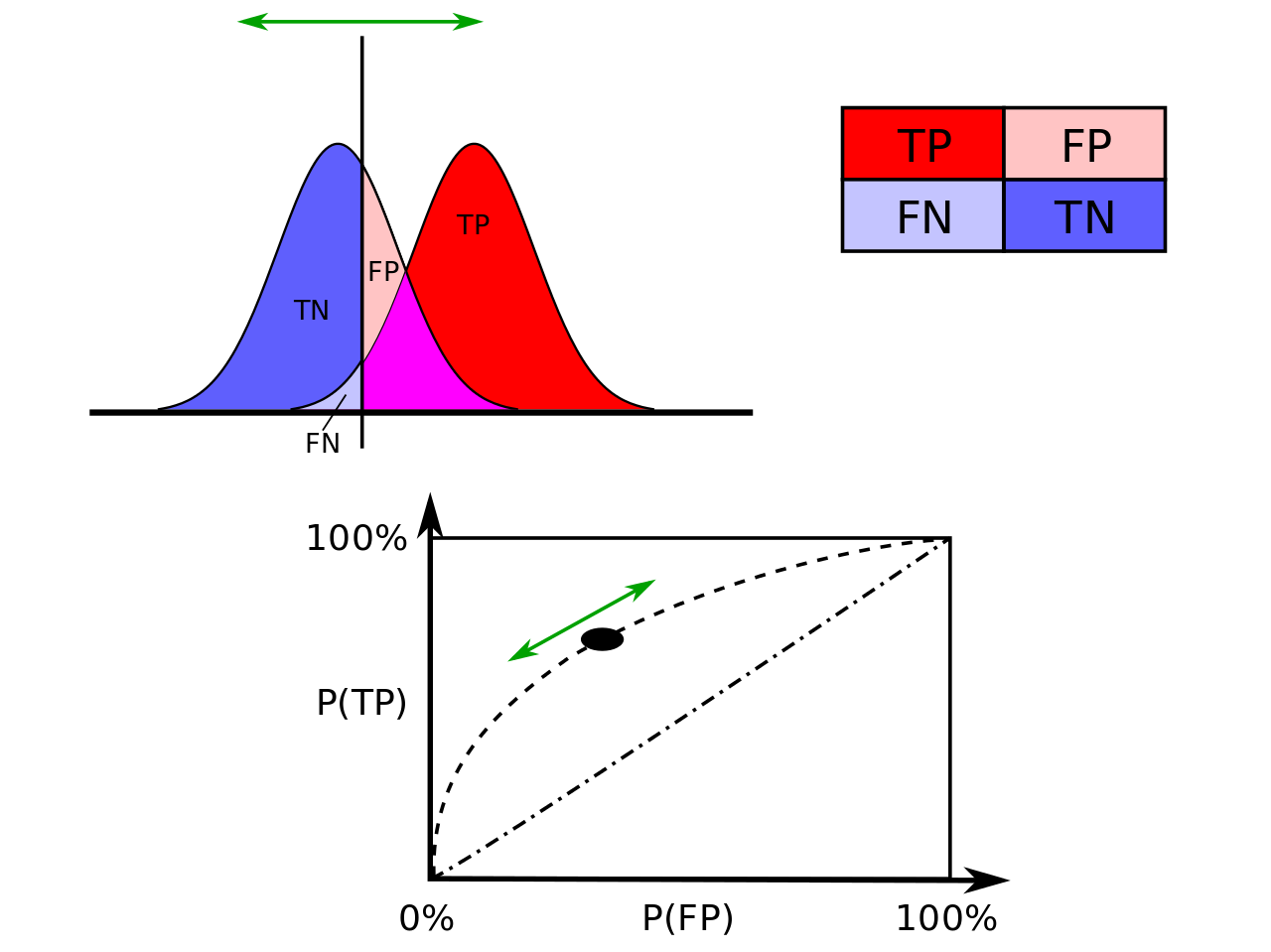
在比较不同的分类模型时,可以将每个模型的 ROC 曲线都画出来,比较曲线下面积作为模型优劣的指标。
AUC :Area Under the Curve of ROC。
因为是在 1x1 的方格里求面积,AUC 必在 0 ~ 1 之间。
AUC 值 = 分类器把一个随机抽取的正例排在一个随机抽取的负例之前的概率(给予正例更高的得分)。
AUC 值越大的分类器,Accuracy 越高。
- 计算方法
根据 FPR 和 TPR 计算,采用梯形积分法(Trapezoidal Rule)。
\[\int_a^b f(x) dx \approx \sum_{k=1}^N \frac{f(x_{k-1}) + f(x_k)}{2} \Delta x_k\]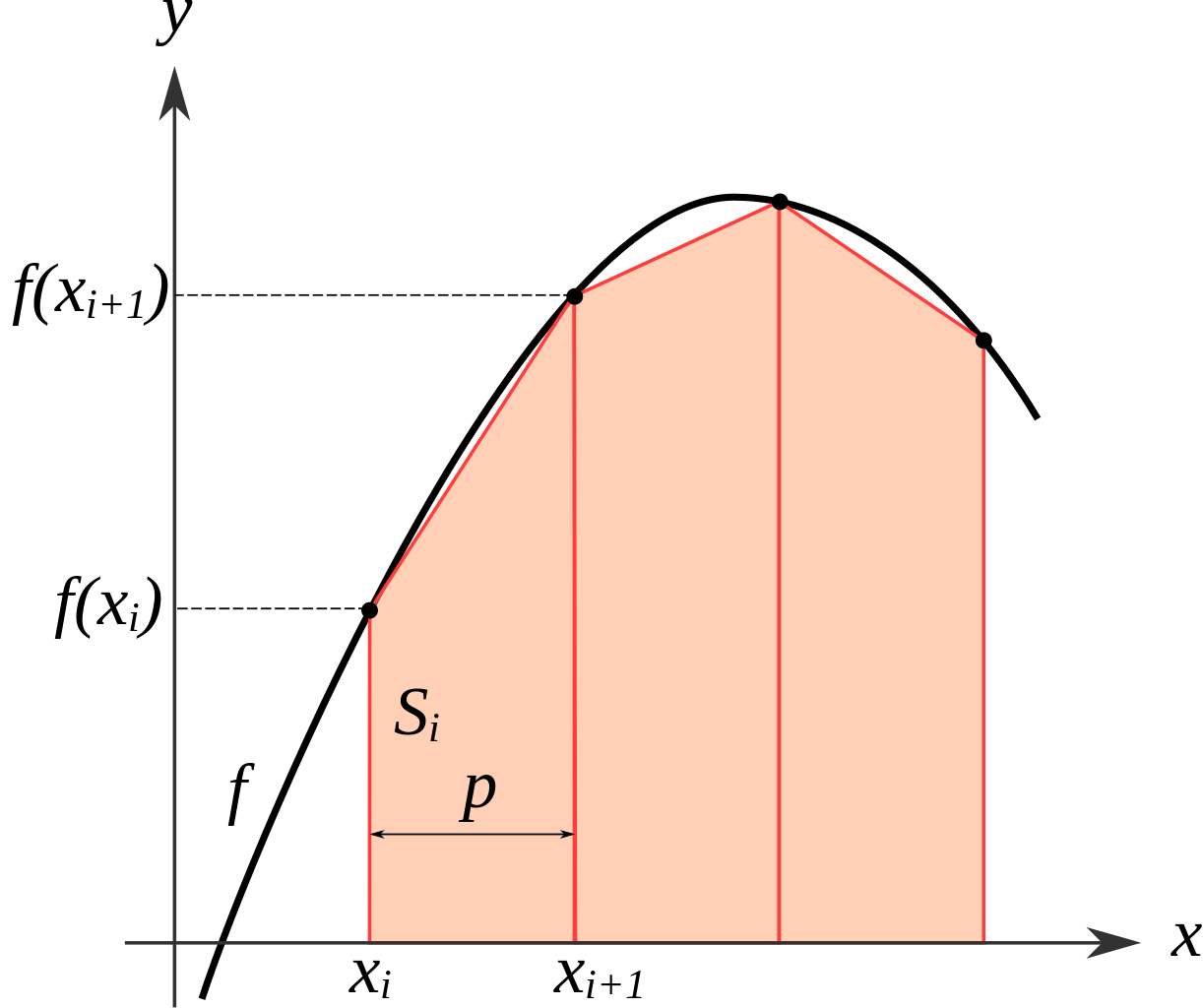
穷举所有的正负样本对,累加分值,除以样本对的数目。
正样本的得分 > 负样本的得分,+ 1
正样本的得分 = 负样本的得分,+ 0.5
正样本的得分 < 负样本的得分,+ 0
1## 方法一
2
3from sklearn.metrics import roc_auc_score, roc_curve, auc
4
5print roc_auc_score(labels, scores)
6
7FPR, TPR, th = roc_curve(labels, scores, pos_label=1)
8print auc(FPR, TPR)
9## auc 与 roc_auc_score 计算结果相同
1## 方法二
2
3def AUC(scores, labels):
4 pos = [i for i in range(len(labels)) if labels[i] == 1]
5 neg = [j for j in range(len(labels)) if labels[j] == 0]
6
7 area = 0.0
8 for i in pos:
9 for j in neg:
10 if scores[i] > scores[j] + 1e-6:
11 area += 1.0
12 elif abs(scores[i] - scores[j]) < 1e-6:
13 area += 0.5
14
15 return area / (len(pos) * len(neg))
AUC 的缺陷
AUC 忽略了模型预测的概率值以及模型的拟合优度。AUC 只对概率值的排序敏感(并且是只对正样本和负样本之间的相对顺序敏感),因此无法衡量模型拟合程度的高低。
AUC 是模型在所有情况下的表现性能的综合体现,但是 ROC 的最左和最右侧区域是比较极端的,一般并不会关注模型在这些情况下的表现。Partial AUC 可以在一定程度上缓解这个问题。
AUC 对 FP 和 FN 同等对待,权重相同,然而实际业务中会有所侧重。
AUC 只是一个标量值,不能提供模型预测误差的分布信息。
在负样本远多于正样本的情形下,模型通过对负样本高估,可以人为地提高 AUC。相同 AUC 的两个模型在不同 ROC 区域的预测能力可能是不一样的。
在搜广推场景下,需要关注的是模型对同一用户不同 Item 的打分能力,这时候一般会计算 GAUC(Group AUC)。
6.3. 参考资料
机器学习之分类性能度量指标 : ROC曲线、AUC值、正确率、召回率
Receiver operating characteristic
ROC曲线
Trapezoidal rule
AUC: a misleading measure of the performance of predictive distribution models